LLM News Pricing Will Not Make Markets Efficient

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Authored On
Modified
LLMs can read financial news faster, but speed does not guarantee better prices The real risk is shared misreading, not just slow market reaction AI trading needs audit trails, uncertainty limits, and stronger governance

A market that could read almost any headline might still miss the news. That is the tough truth behind LLM news pricing. In recent research on news and returns, the part of the news text that was not already foreseeable from firm characteristics more than doubled the monthly explanatory power of raw news to predict returns. It also continued to predict returns for up to 18 months. That is a significant reality. It suggests that markets do not simply overlook data; they overlook meaning. They often price the forecasted number before they stumble over the unsaid words. Now, large language models are present to interpret those words at greater speed, lower cost and larger scale. But speed isn't equivalent to insight. If many trading systems interpret the same language, the next market crash may not be a sluggish response. Instead, it may be a collective misinterpretation.
Why LLM News Pricing Changes the Problem
The new policy question is not whether language models read financial news. They can. The better question is, can LLM news pricing transform confusing language into better prices, or only transform high prices into fast, consistent trades? This shifts the problem from one of access to one of interpretation. For years faster access to market data was the end game. Firms bought terminals, data feeds and dedicated, low-latency pipes because delay was expensive. But the toughest part of the news is no longer speed. It is the distance between expected language and actual surprise. Earnings, sales, debt and margins are already being read by models, investors and banks. When a report drops, much of it has been anticipated, hedged and priced in terms of the numbers by the time it hits the public sphere. The rest of the language can still matter, though, because it is where doubt, emotion, delay, blame and source can be hidden.
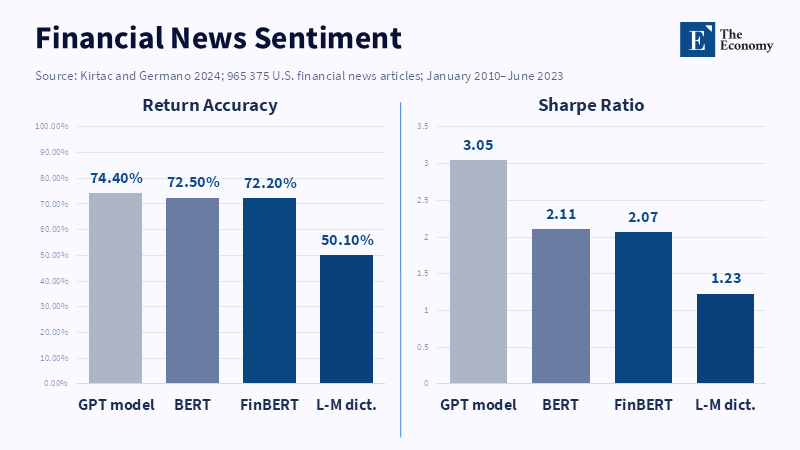
That is why the value of LLM news pricing should never be conflated with a painless fix for market efficiency. An LLM can read more articles than a desk, assign sentiment tags, distill events and compare the wording of many past cases. Academic work on financial news from 2010 to 2023 finds LLMs can classify sentiments in ways consistent with return-predictability, with one GPT-based model reaching 74.4% return-direction accuracy in the tested setting. Other papers show ChatGPT-style scores of headlines are capable of predicting daily return signals, mostly for smaller companies or negative news. That work is critically important. It does not establish that an LLM "knows" intrinsic value. It demonstrates that language still bears predictors that move the market slowly and that, in certain instances, machines may discover them ahead of the market. Policymakers should be concerned when that narrow advantage is set forward as a license to automate judgment generally.
Pure News Is Not Noise
Pure news is what was not implied already by the firm’s present profile. This is a crucial distinction. If a weak firm reports weak margins, there may be little to learn. If the same firm uses new language about demand, supply, legal risk, or cash pressure, the language itself may be revealing. The surprise is not necessarily in the table. It can be embedded in a phrase that alters investor perceptions of the coming year. That is why sentimental language should not be dismissed as fluff. Words often herald risk well ahead of the figures. A firm can state "soft demand" long before the balance sheet turns sour; cite "reviewing strategic options" even before an auction is underway; sound a warning about "temporary pressure" long before a larger problem becomes visible.
The mispricing of news, then, does not mean that investors are gullible because they respond to tone. Perhaps it means that language is the earliest public setting where fallible facts take shape. The difficulty is that markets treat every meaning differently. They may underreact to objectively negative, slowly forming messages. They may overreact to certain significantly attended, emotionally charged, or vague narratives. LLM news pricing could even tell the difference. But that requires the model to pose a tough question: What part of this was already anticipated? A model that simply classifies an article as good or bad will miss out. What's informative in that case is not sentiment per se, but sentiment after objective information, company characteristics, previous price movements and industry states have been conditioned out. That is the practical line between understanding news and merely responding to language.
From Inefficient Pricing to Incorrect Pricing
The problem is that LLM news pricing could shift markets from mismatched prices to wrong prices. Mismatched prices mean markets are inefficient, slow, too emotional and too anchored. Wrong prices mean that the machine constructs a false link between words and value, then trades on it decisively. It is not an abstract risk. Large language models (LLMs) create false assertions in fluent language. A 2026 Nature paper argues that accuracy tests reward guessing if models are told to admit ignorance. Finance provides an even more glaring problem. If a model constructs a causal story around a headline, it may as well have created the trade, the risk limit and the portfolio rebalance. When copied across many systems, a small mistake becomes a price.
In a financial market context, hallucination is more expensive because the truth takes longer to reveal. An incorrect summary of a recipe can be verified instantly. An incorrect reading of a regulatory probe, supply shock, or merger rumor may take months to dissipate. Studies of financial information gaps reveal that LLMs may be better on bigger, more recent firms, but still more likely to hallucinate in some of those same areas. This affects LLM "news" pricing because attention is highly concentrated. The biggest firms lead to the most text. Their stories are louder, more heavily linked to historical trends and in all cases, their corpus may be denser. It seems natural that LLMs feel most assured when the text trail is dense, even if the data event itself is new.
The Market Risk Is Herding, Not Just Errors
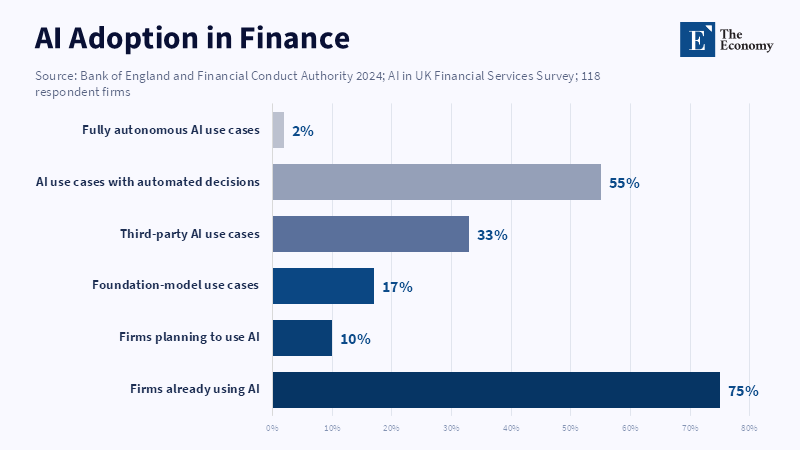
It's more likely to be a group of LLM news pricing systems simultaneously affecting one way. The more they are aligned, the greater the risk of systemic mis-pricing. The 2024 UK survey conducted by the Bank of England & the Financial Conduct Authority found that 75% of financial firms said they use AI, with another 10% expecting to do so in 3 years. Foundation models comprised 17% of these use-cases. Third parties were responsible for 33% of all AI use-cases and the three largest service providers held substantial shares of cloud, model and data providers. 55% of AI use-cases had some form of automated decision making, despite only 2% being fully autonomous in operation. A market structure problem. The more firms use similar models, data vendors, prompts and sentiment labels, the more likely "independent" trades may be correlated.
That's why, even if firm-level model risk is known, regulators should consider the possibility of system-wide crowding. A bank may have validated its own model but still continue to be crowded on the aggregate. A fund may have understood its own signal and still be crowded on the same trade as rivals. The Bank of England has issued a warning that wider AI use in trading could increase firms' determination to take more correlated positions in times of stress, making shocks bigger. That's a good fit for the classic news problem. Bad news comes in clusters. An earnings miss hits rivals. A one-sentence court ruling hits the whole sector. A single central-bank phrase hits rates, equities and FX in unison. If multiple models acted in the same way on the same phrase because they've learned the same frame, the market move on that phrase might have appeared to be the result of optimal integration, when in fact it was just the result of maximum uniformity.
A Governance Test for LLM News Pricing
The correct solution is not simply to ban LLM news pricing; that is too optimistic, too naive. The tools are too valuable for search, screening, translation, summarization and event tagging. The challenge is to prevent firms from viewing a language output as a price indicator that they can use without robust constraints. All trading activity based on an LLM should have three features: separate the characteristics of known future content from genuine news, show the inherent uncertainty in a form that can constrain position size and be compared with existing market data, source documents and competitor models before it affects risk. These are not heavy constraints. They are basic safeguards, fundamental checks on a method that converts words to capital flows. A modest restriction would categorize each model output by three states: verified unexpected news, indeterminate text, or no trade. That would put doubt into practice, rather than mere posturing. For boards, chief risk officers and regulators, the criterion should be obvious: can the team produce a justification before the trade, rather than simply prove the trade?
Supervisors will also want more transparent disclosures. In 2024, the US Securities and Exchange Commission sanctioned two advisers for making false and misleading AI representations, levying a total civil penalty of $400,000. That case concerned messaging, but the conclusion extends to trading. It should be clear whether investors are hiring AI for research, choosing to act on AI, or relying on it to trigger an order. It should be possible for supervisors to request several layers of audit trail, including document, prompt, model version, output, human review and trade. The goal is not to publish each model. It is to provide clarity on responsibility. A market cannot efficiently price a news event when no one can explain how the news resulted in a position.
The most obvious criticism would be that these controls will inhibit innovation and punish the best first movers. That is to miss the point. LLM news pricing can only have value if it is better at interpretation. If it is fast but cannot distinguish surprise from repetition, it adds noise. If it is confident but cannot allow for uncertainty, it adds false precision. If it is widespread across desks without stress testing, it adds herd risk. In fact, any controls that are strong will not kill the signal. It will only safeguard it from its own scale. The strongest firms will not allow models to trade every headline but those that know when not to trade. In markets, restraint is not a lack of skill. It can often be the proof of skill.
Another criticism that can be raised is that markets will correct their mistakes themselves. They will at times. But the delay in correction can be so high that it still affects capital allocation. Prices signal credit, share buybacks, acquisitions, compensation and household assets. An incorrect interpretation of news may increase the cost to finance a firm or incentivize weak disclosure. It may also drive attention toward sensationalist language and away from gradual facts. But the first fact still remains the touchstone: pure news can move prices for many months, thus language is not merely the surface of markets, it is integral to the pricing system. As such, the pricing of LLM news needs to be governed as the infrastructure of markets, not as a nice-to-have for research. Inevitably, it will not be possible to bring news into prices for every sentence, but it should be reasonable to implement a more truthful pricing of uncertainty, with algorithms that read quickly, doubt precisely and only trade when the signal is truly interpreted.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
Bank of England (2025) Financial Stability in Focus: Artificial Intelligence in the Financial System. London: Bank of England.
Bank of England and Financial Conduct Authority (2024) Artificial Intelligence in UK Financial Services – 2024. London: Bank of England and Financial Conduct Authority.
Didisheim, A., Kelly, B.T., Pourmohammadi, M. and Tian, H. (2026a) The Inefficient Pricing of News. NBER Working Paper No. 35093. Cambridge, MA: National Bureau of Economic Research.
Didisheim, A., Kelly, B.T., Pourmohammadi, M. and Tian, H. (2026b) ‘The inefficient pricing of news’, VoxEU, 27 May.
Kalai, A.T., Nachum, O., Vempala, S.S. and Zhang, E. (2026) ‘Evaluating large language models for accuracy incentivizes hallucinations’, Nature, 653, pp. 1047–1051.
Kirtac, K. and Germano, G. (2024) ‘Sentiment trading with large language models’, Finance Research Letters, 62, Article 105227.
Lopez-Lira, A. and Tang, Y. (2023) ‘Can ChatGPT forecast stock price movements? Return predictability and large language models’, SSRN Electronic Journal.
Securities and Exchange Commission (2024) SEC Charges Two Investment Advisers with Making False and Misleading Statements About Their Use of Artificial Intelligence. Washington, DC: SEC.
Shah, A., Ye, L., Jaskowski, S., Xu, W. and Chava, S. (2025) Beyond the Reported Cutoff: Where Large Language Models Fall Short on Financial Knowledge. Atlanta, GA: Georgia Institute of Technology.
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
















