The Next AI Ranking Will Measure the Firm, Not the Model

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Authored On
Modified
Agentic AI evaluation must measure firm capacity, not just model quality The real AI divide is between adoption and trustworthy scale Strong firms will prove control, value, oversight, and workforce readiness

Τhe fact that nearly 90% of organizations are using AI in their business in some form or other, while few are beyond pilots into scaled value, says nothing about what I am really interested in: the evaluation of agentic AI. It is no longer enough to believe the AI agent can perform some task in a controlled, experimental setting. The difficult question now is whether a firm can provide enough operating slack inside its existing systems to give agents free rein without sacrificing control, trust, cash, or brainpower. Evaluating agentic AI, then, has to happen at a higher level: it must assess the answer the agent gives along with the company’s operating fitness, its data, its tooling, flow design, audit trail, human monitoring, security and ability to learn from failure. In other words, agentic AI is not purely a software upgrade. It is a test of corporate maturity.
Agentic evaluation of AI needs to measure firm capacity
The evaluation for the first kind of AI was on the quality of the model. That made sense when your main product was a chatbot or a text generator. Freshness, bias, safety, relevance, responsiveness and "quality of text" made sense. But an agent is different. It can plan, call tools, update records, trigger workflows, and upload work to other agents. It is more like a semi,mobile junior operator with access to a world of software than a static model. The firm providing such a system is not just purchasing intelligence; it's endowing the firm with agency. That changes the policy question. A strong agent in a weak firm could be more dangerous than a weak agent in a strong firm. The firm's capability becomes part of the technology.
Hence, agentic AI evaluation should not only treat it as a product but also treat it as the organizational norm. For instance, the organization might claim that its agent saves time in customer service, finance, compliance, coding, procurement, or internal search. On the other hand, such an organization might still not have clean process maps, steady data permissions, defined handoff rules and logs to record how the agent was acting. In such cases, the claims of AI readiness are very superficial. The organization has simply harnessed speed into a slow and chaotic setup. Agentic AI evaluation should firmly identify such gaps. It should find out whether the organization is able to define the task, bind the agent, monitor the action, identify the mistake and present the outcome afterward.
A firm, capacity lens also recasts the questions we want rankings to answer. We want a ranking to do this, not use AI maturity as a press release, or a spending level, or a count of models. We want a ranking to do this, use it as evidence of disciplined action. Can the firm show what agents touch what systems? Can it separate low-cost support tasks from costly decisions? Can it show when a human must authorize a step? Can it measure if agents open-loop work early in a cycle, without adding hidden overhead during review? These are trivial questions; they are not easily faked. They also distill agentic AI evaluation down to a basic execution test. And they reward organizations that deliver lasting infrastructure: firms that are shipping stable systems, as opposed to firms that are merely showing demos.
Agentic AI evaluation is emerging as a market standard
There are now a handful of competing standards defining this space. The Brookings-Carnegie Mellon agenda is the best in measurement science. It cautions that benchmarking icons can’t predict real behavior, especially when agents behave over time and interact with users, tools and changing contexts. NIST is wider in the risk space through its AI Risk Management Framework and its generative AI profile. ISO/IEC 42001 is wider still on the management,systems, logic, policies, goals, controls, continuous improvement and accountability. And the EU AI Act is the widest, backed by legal provisions that apply when AI may impact rights, safety, labor, or ease of access. Commercial tools, including DeepEval, LangSmith, OpenAI Evals, Ragas and AgentOps platforms, add the execution of test cases, traces, graders, datasets, online monitoring and regression checks.
These are not the same things. Some ask if the agent provides a good answer. Some ask if the agent selected the appropriate instrument. Some ask if the entire system remains policy-compliant. Some ask if the organization maintains AI oversight governance. But the market needs today a link that combines these. A rigorous firm,capacity threshold must encompass five layers: strategic intent, technical control, workflow transformation, risk design and measurable business value. It should not recognize agent acquisition. It should recognize firm accountability to demonstrate agent, enabling work enhancements that do not come at the cost of added errors or displaced responsibilities.
The economic argument makes this urgent. In its 2025 survey, McKinsey found 88% of respondents reporting regular AI use in at least one business function, 62% at least experimenting with AI agents, but only 23% scaling an agentic AI system somewhere in the enterprise. No business function had more than 10%of its respondents already scaling agents. That is the capacity gap plainly on display. Firms show interest. Many are testing. Few have acquired the operating muscle to scale. Agentic AI accounting should expose the gap, compare it with other enterprises and make it difficult to ignore.The new labor question is not replacement alone. The labor question reflects two distinct problems: whether economic growth transmits increased income to the working class and how to provide more jobs. One is part of Keynesianism, the other of capitalism's contradictory nature.

The classic labor debate is about whether agentic AI will replace human workers. This is the wrong question. The interesting question is which firms will be able to turn agentic AI into a new form of productive labor. A high-capacity firm will be able to compress routine work into agents; simultaneously, they will be able to give a highly skilled employee a broader span and push out weak coordination layers. A low-capacity firm will succumb to automation narcissism and produce rework, blaming the model. So the discussion of superhuman labor must be anchored back into institutional capacity. Agents do not displace bad work through magic. They displace it through the ability of a firm to turn a task into a clear system, to ship out the tools that make agents effective and to hub a human at those points that require judgment and taste.
This is also why mediocre human work is not equivalent to human work. The intent is not the individual. The target work is habit-driven and evaluated through opaque metrics. An agentic AI can take on this layer in a clear enough task and a mature enough firm. But it also increases the value of the human skills of designing the task, reviewing exceptions, improving prompts, testing outputs and understanding the business context. This labor market effect will be patchy. Some jobs will shrink. Some jobs will be reinforced. And some jobs will be redesigned around agent supervision.
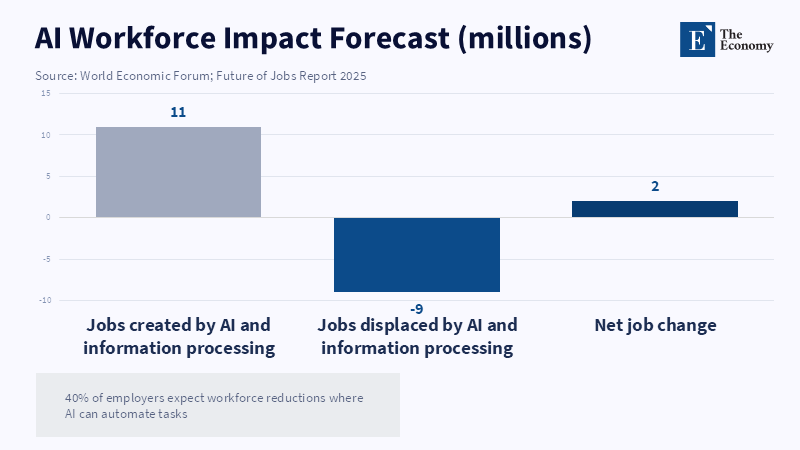
The signs point that way. In its most recent global surveys, the World Economic Forum reported that 40 percent of firms expect to lay off people where AI can do their jobs. The WEF also said that trends in AI and information processing systems should lead to an additional 11 million jobs displaced for every 9 million created. These figures should not be interpreted as predictions of absolute job losses; they are indications of orderly dislocation. Work is being sorted; tasks that train junior employees may now be delegated to agents and entirely new jobs will be created once evaluation and audit, security, data quality, workflow design and domain monitoring become central to running AI systems. The companies that win will not be the ones that slash jobs the fastest, but the fastest at redesigning work without losing their talent bed.
This is important for management and policymakers since the first cost of weak agentic AI adoption may be hidden. While a company may save an hour today by letting agents write, search, sort, or act, it may be impoverishing the middle layer of its future workforce if junior-level workers lose the experiences that have always built real competence in the firm. And it may be losing its savings if senior stakeholders have to continually correct for agent mistakes. And since accountability is often not invested in any one person, risk can walk from the task to the entire institution. As with all new AI applications, workforces should be among the criteria when evaluating agentic AI. We should question whether the company is using agents solely to free humans from initial steps or to build their skills through them.
Agentic AI assessment requires Evidence of control
A good benchmark has to evaluate behavior, not slogans. One recent agent evaluation platform demonstrated how that could work. For a CloudOps agent, a scenario with 100% task completion still demonstrated memory recall of just 13.1%, with an 18.1% memory F1. Yet a different scenario came in with perfect tool sequencing but only 33% policy adherence. That's an important lesson for companies. Finished can conceal flaws. An agent may look finished, while actually missing a policy check, lacking the proper context, having used a tool in the wrong sequence, or having built an unstable result that will ultimately fail.
The same logic can be applied throughout: In financial services, an agent that expedites a loan review but violates a compliance rule is not successful. In health services management, an agent that expedites patient care but violates privacy rules is not successful. In procurement, an agent that expedites the purchase of a low-cost supplier but violates sanctions, quality history, or delivery risk is not successful. In educational services, an agent that expedites student response but violates student,matching, disability, or fee rules is not successful. The agent score must be tied to the solution. The basic question is not: "Did it finish?" Instead, it is: "did it finish with enough evidence to trust the result, according to that firm's control system?"
This is where the standards of today’s market should come together. DeepEval and similar tools enable teams to deploy component-level and end-to-end testing. LangSmith and OpenAI's evaluation packages make traces and graders focus points for improving agents. NIST and ISO supply the governing language. The EU AI Act applies legal incentives toward risk management, logging, human oversight, truthfulness, fairness, robustness and cybersecurity in high-risk settings. But a firm capacity standard should distill these into a ranking system. For example, it should measure whether a firm has an agent inventory, a permission map, a test data set, a red team report, an application monitor, an incident response plan, a cost monitor, an environmental cost monitor, a human review policy and an executive team stake in incident response.
The most likely rebuttal to these proposed standards is that they will hinder innovation. While this may seem like a natural reply, it fails to hold up under scrutiny. Bad evaluation already damages innovation, as it allows firms to place bad pilots in production, with no repercussions. It fosters large firms, as they can afford to incur the potential costs of a bad deployment, while smaller firms will take a reputation or legal hit. A clear agentic AI evaluation standard would reduce the level of uncertainty in the field, ease the comparability of vendors for buyers, ease the assessment of which firms have to build actual AI capacity for investors and ease the understanding of how agents will shift roles for workers. The standard does not need to demand perfect safety, but rather, honest evidence. Firms should be able to demonstrate their agents' capabilities, what they cannot do, which humans monitor them and the exact moments they must cease operation.
The more profound takeaway is that agentic AI will illuminate the gulf between spectacle and real operational muscle. A large number of companies will feature agents. A very small number will package capacity. The next serious ranking of AI should not be based on which company has purchased the most tools or launched the biggest automation push. It should be based on which company is capable of converting agentic AI into reliable, governed, value-adding work. And this means realizing evaluation as an infrastructure. It means testing agents in their context, calculating costs alongside speeds, grouping metrics around true labor impacts and integrating audit trails as everyone expects. 85% of firms may already deploy AI somewhere13 and the next split will be between firms that use agentic AI and those ready to be trusted.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
Akshathala, S., Adnan, B., Ramesh, M., Vaidhyanathan, K., Muhammed, B. and Parthasarathy, K. (2025) ‘Beyond Task Completion: An Assessment Framework for Evaluating Agentic AI Systems’, arXiv preprint, arXiv:2512.12791.
Autio, C., Schwartz, R., Dunietz, J., Jain, S., Stanley, M., Tabassi, E., Hall, P. and Roberts, K. (2024) Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. Gaithersburg, MD: National Institute of Standards and Technology. DOI: 10.6028/NIST.AI.600-1.
Di Battista, A., Grayling, S., Játiva, X., Leopold, T., Li, R., Sharma, S. and Zahidi, S. (2025) The Future of Jobs Report 2025. Geneva: World Economic Forum.
European Parliament and Council of the European Union (2024) Regulation (EU) 2024/1689 of 13 June 2024 laying down harmonised rules on artificial intelligence. Official Journal of the European Union, L 2024/1689.
International Organization for Standardization and International Electrotechnical Commission (2023) ISO/IEC 42001:2023: Information Technology — Artificial Intelligence — Management System. Geneva: ISO.
Singla, A., Sukharevsky, A., Hall, B., Yee, L., Chui, M. and Balakrishnan, T. (2025) The State of AI: Global Survey 2025 — Agents, Innovation, and Transformation. New York: McKinsey & Company.
Tabassi, E. (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Gaithersburg, MD: National Institute of Standards and Technology. DOI: 10.6028/NIST.AI.100-1.
Tabassi, E., Krishnan, R., Munkhbayar, E., Nadgir, N., Belle, D. and Dzombak, R. (2026) ‘How can we best evaluate agentic AI? A Brookings-Carnegie Mellon University workshop recap’, Brookings Institution, 24 April.
Vongthongsri, K. (2025) ‘LLM Agent Evaluation: Assessing Tool Use, Task Completion, Agentic Reasoning, and More’, Confident AI, 10 October.
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
















