The Bill Comes Due for Cheap AI

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Authored On
Modified
Cheap AI is becoming expensive infrastructure Usage limits reveal the real cost of heavy AI use The next AI race is about compute, power, and pricing

In late March, heavy Claude users ran into a new kind of shortage. Twenty minutes of a 5-hour usage session could result in the user being cut off. These disruptions proved a broader point: the AI compute crunch is no longer just a notion. Now, it is a matter of being locked out, of tools that are sluggish and of limits and prices that have become significantly harsher. When they initially promised a flat-rate structure, this signaled that every result was free. However, the days of this cheap offer are drawing to an end. Every prompt sent requires chips, memory, electricity, a network connection and engineering expertise. Heavy users don't just ask for a few more prompts; they want a larger token quantity, more sizeable files, more powerful agents and even larger working memories. The end result is that cheap AI was never meant to be anything more than a subsidy.
AI Compute Crunch: A Price Signal, Not a Glitch
It is important to treat the AI compute crunch as a price signal. Prior to delving into the reasoning behind this assertion, one must first appreciate that these usage limitations, however frustrating to the consumer, were implemented not merely as product preferences. Instead, they indicate the inability of a system to affordably satisfy everybody's uniform demand for machine time in massive quantities at a singular, fixed cost. This represents a monumental shift in perspective, as although many consumer-oriented AI products were billed as lightweight as the Web, they have come to behave more like power plants, data centers, or logistical networks. A text box may seem immaterial, but the machinery behind it is anything but light. Most importantly, models, as they migrate from being casual chat applications to code-generating agents, research aids, design applications and workflow automation tools, have become far more expensive to run per task. A quick question is not a cost; a session that has to work on writing, reading, testing, retrying and improving files over many hours most certainly is.
Claude's limitations were clarified when the users' dissatisfaction arose from the service provider's financial burdens. This became a turning point and changed how the topic of usage and sustainability was being discussed. Anthropic has now begun to advise paid customers on how to monitor usage limits, both on a per-session basis and a weekly basis, while also making them aware of the token costs associated with varying message lengths, file sizes, models chosen, conversation history and tool utilization. This differentiation is critical: the user perceives a prompt; the service provider sees tokens, tools, GPUs and overall peak load. While $20 or $30 monthly fees were suitable for short, infrequent prompts, they have now become insufficient for the user who is now working on agentic tasks for multiple hours daily. The solution is not in issuing more warnings, which are helpful, but in determining how AI access can be concealed within the realm of its actual expenses.
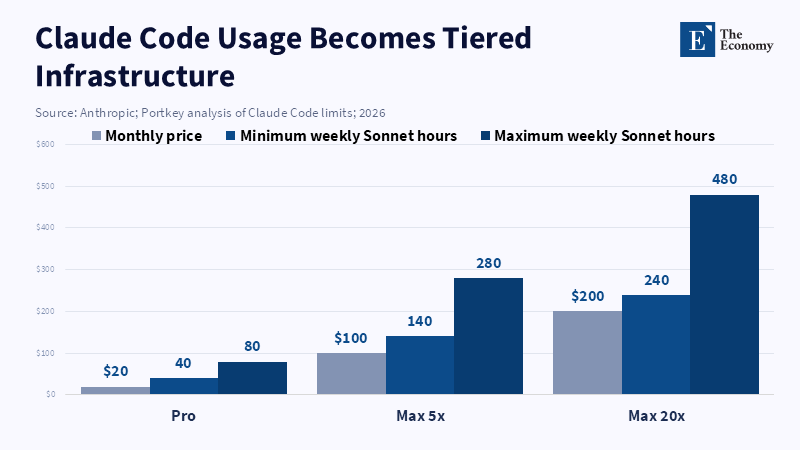
The $30 AI Subscription is Crumbling
Fixed-rate AI costs are premised on an unspoken intra-subsidy. Customers who don't utilize a lot of resources end up overpaying relative to their use of them, whereas heavy users are effectively undercharged. The costs are like those incurred when software companies market a flat fee, but here the discussion must shift from the consumer's perspective to industrial economics as a whole. The context is now far more significant with ongoing high hardware and energy costs. Anthropic announced in July 2025 that its new weekly limitations would not have an impact on over 95% of its users, yet their own hypothetical case study showed that one user had utilized thousands of dollars worth of models while only paying $200 per month. This is not a technical support issue; this is an issue of core unit economics. And this is a problem that is now prevalent throughout the entire sector. GitHub made it known in April 2025 that their Copilot service will move to a usage-based model beginning in June 2026 because they could no longer ignore the difference between a quick chat and a lengthy autonomous coding session.
Hardware is also a contributing factor to the cost. AI computations are not uniformly decreasing in expense. While certain software interactions may be less expensive, high-end hardware continues to be in short supply. In the space between October 2025 and March 2026, the price for an H100 chip rental grew by roughly 40 percent. NVIDIA B300 servers in China rose to $1 million each, an amount that is close to double what U.S. Companies are paying. Although these are only ballpark figures, the narrative is consistent: hardware scarcity is slowing down the advancement of AI. Demand is consistently higher than supply, which ultimately leads to queuing, capacity constraints and higher prices. The user sees constraints; the provider sees escalating costs.
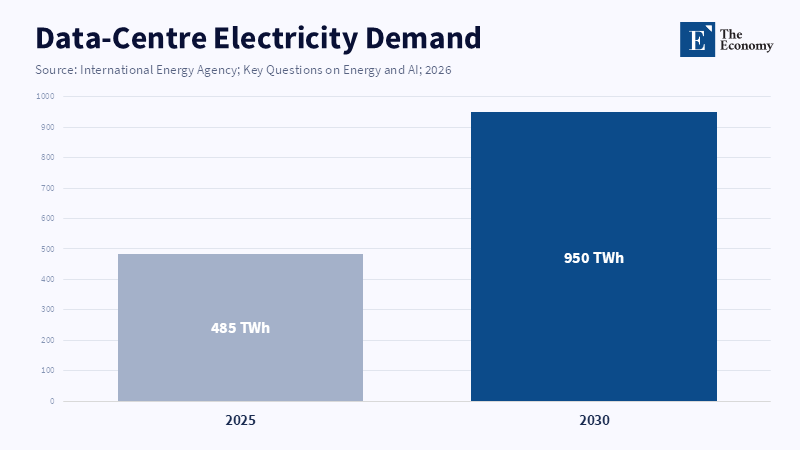
Electricity also adds to the cost. According to the International Energy Agency, the electricity used by data centers is projected to jump from 485 terawatt-hours in 2025 to 950 terawatt-hours in 2030. Based on one particular prediction, energy consumption will reach 460 terawatt-hours in 2024 and exceed 1,000 terawatt-hours by 2030. Goldman Sachs Research estimates that between 2023 and 2030, the amount of electricity required for data centers will increase by 165 percent. Despite variations in baseline figures, the trajectory is clear: AI is now in direct competition with the grid, transformers, cooling systems, land and green energy agreements.
Therefore, 'revenue below cost' should be assessed at the workload level rather than solely at the organizational level. Even though major AI corporations may be boasting record revenue figures (OpenAI, for example, reported over $20B in annual revenue for 2025 and a corresponding increase in compute load from 0.6 GW to 1.9 GW for the same year), they were simultaneously investing $600B in compute power through 2030. The cost of inference more than doubled between 2024 and 2025. This is not necessarily an indicator that every AI company is running at a loss per user; rather, the users who treat their flat-rate subscription as an open-ended allowance for machine labor are proving to be exceptionally unprofitable. Once this truth comes to light, subscription plans move from being considered a bundle of services to being a form of metered utility.
When Human Labor Is Seen as Cheaper than AI Labor
Perhaps the most disconcerting outcome of all is the possibility that human labor is becoming more cost-effective than AI labor, at least in the near term. This is a crucial distinction in the analysis and introduces an entirely new comparative element between human and AI costs. Although this may sound ironic given that AI is often advertised as a labor-saving technology, it becomes clear when one examines a complex, resource-intensive task in which an AI worker runs for several hours. U.S. Software developers earned a median annual wage of $133,080 in May 2024. While significant, if a single user is spending tens of thousands of dollars on model usage while paying only $200 monthly for the service, then AI labor without proper oversight is actually more expensive than skilled human labor. This is not to say that AI is not valuable. It simply indicates that the simplistic narrative of 'AI as a less expensive alternative' is inaccurate.
While AI is clearly useful for many tasks like document drafting, text summarization, language translation, first-pass code review, test generation and search assistance, it is vital here to differentiate between the creation of an output and the use of labor, as well as between the concepts of labor and autonomy. Human employees operate under specific wages, hours, supervisors and budget constraints, whereas AI agents are nothing more than streams of tokens. If the context, retry mechanisms, tool usage and model choice are not managed correctly, an AI agent can quickly incur massive expenses without necessarily delivering useful output. Therefore, the AI compute crunch has also evolved into a management challenge. The businesses that prevail will be those that can implement small models for smaller tasks, allocate the most powerful models to complex problems, cache contexts to reduce redundant operations, enforce time limits for agent execution and track costs on a per-task basis.
This calls for an entirely new approach to how institutions, public buyers and firms use AI. Schools, universities, agencies, or companies can't simply buy AI as another seat license if a few users consume 80% of its budget. Although easy to approve, seat licenses mask risk. Pay-per-use is hard to explain, but it shows the actual trade-off. The right policy isn't prohibiting heavy use; some heavy use generates immense value; it's demanding accountability for it. Institutions need to develop dashboards to show usage across tokens, models, peak load, cost-per-workflow and rules that allow learning and experimentation while preventing hidden waste. Cheap AI isn't the same thing as open access.
The counterargument is that this will be temporary. Chip efficiencies will grow, models will shrink and inference will become cheaper. Some of that will be true: there will be progress in model size, caching and hardware speed. But demand won't stand still; lower prices increase demand. Users will move from questions to agents, from typed inputs to huge files with attachments, tools, images, audio, video and lots of context. This rebound effect is already occurring in coding assistants: their improved capability will encourage longer, more sustained use. The correct policy question, therefore, is not if, but if and by how much, efficiency is growing relative to demand.
What Users, Firms and Policymakers Should Do Next
The obvious first action step is also directly responsive to the earlier discussions about policy failure. AI providers should immediately stop advertising "unlimited" exposures while secretly setting hard ceilings and they need to adopt easily understandable public usage monitors with clear guidelines for reset and concrete examples explaining what different levels of context length, document attachments, tool usage, or model switches would cost. Users will not object to reasonable, visible limits but they will rage at what appears to be an arbitrary exclusion. If a 5-hour context window is disappearing in 20 minutes that’s a valid business decision, but its invisibility is a management failure. The explicit intention of "smart pricing" is not to force revenues, but to show the actual cost of intelligence before a sudden shutdown.
Beyond performance, organizations must push vendors to demonstrate their real-task costs. A very advanced demo model may be entirely too costly for routine operations than one that reliably addresses 80% of regular tasks. Procurement must perform relevant file-and-user testing to establish the actual token cost and turnaround time. Educators and administrators may allow universal access for risk-free learning, but agent use cases, bulk file upload and intensive models must be carefully managed, not banned, but explicitly controlled.
Data centers rely on electricity, water and land and their needs call for upgraded power grids and streamlined permitting. To achieve sovereign AI, a nation needs the electrical capacity and a simpler path to permitting, but it must also avoid creating a market where compute is effectively allocated and prices set by a few major players who can secure early access to chips and favorable, long-term power deals and absorb early losses while competitors limit their offerings. The implicit subsidy creates an environment where early access is cheap but a market underwritten by state resources is later monopolistic and overpriced. Open standards, energy disclosure, efficient models and competitive computing access is key.
In the end, the AI compute bottleneck is not a precursor to an AI boom, but rather the place where the boom confronts its actual costs. The Claude limits, the Copilot changes, the spike in GPU rents and the power forecasts all signal the same truth: intelligence is not weightless and it comes with a real cost to be borne and managed. The next era of AI is not defined by aspiration but by the efficient use of a finite resource for tangible benefit. Users should insist on transparency; organizations must view AI as a new kind of public utility; and policymakers must treat computing and energy as a unified industrial complex. Although niche uses of AI may remain inexpensive, ubiquitous AI will not.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
Anthropic (2026) ‘Usage limit best practices’. Claude Help Center, 16 March.
Babu, J. and Rooprai, A. (2026) ‘OpenAI expects compute spend of around $600 billion through 2030, source says’. Reuters, 20 February.
Béchard, D.E. (2026) ‘What is the AI compute crunch—and how will it affect chatbots?’ Scientific American, 1 May.
Bureau of Labor Statistics (2025) ‘Software Developers, Quality Assurance Analysts, and Testers’. Occupational Outlook Handbook, 17 April.
Ellis, M. (2026) ‘I almost ditched Claude over its brutal rate limits, but then it nailed something no other AI could’. XDA Developers, 3 April.
Ha, A. (2026) ‘Anthropic says Claude Code subscribers will need to pay extra for OpenClaw usage’. TechCrunch, 4 April.
International Energy Agency (2025) Energy and AI. Paris: International Energy Agency.
International Energy Agency (2026) Key Questions on Energy and AI. Paris: International Energy Agency.
Kalia, K. (2026) ‘OpenAI CFO says annualized revenue crosses $20 billion in 2025’. Reuters, 19 January.
Pan, C., Mo, L. and Chen, L. (2026) ‘Prices of Nvidia’s B300 server at $1 million in China on US curbs, sources say’. Reuters, 30 April.
Parsons, J. (2025) ‘Anthropic is putting a limit on a Claude AI feature because people are using it “24/7”’. Tom’s Guide, 29 July.
Rodriguez, M. (2026) ‘GitHub Copilot is moving to usage-based billing’. GitHub Blog, 27 April.
Schneider, J. (2025) ‘AI to drive 165% increase in data center power demand by 2030’. Goldman Sachs Research, 4 February.
SitePoint Team (2026) ‘Claude Code Rate Limits Explained: Why You Hit “API Error” at 6% Usage’. SitePoint, 13 March.
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.