Escaping the AI Research Arms Race

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Published
Modified
Federal AI spending alone no longer secures United States dominance after decades of relative decline. China is sprinting ahead as AI-driven “super-human” productivity makes vast swathes of labour redundant. Research budgets must be tied to strong worker protections to win the tech race without fracturing society.

A single statistic captures why America's science policy now stands at a crucial point. In 1964, federally funded research and development accounted for 1.86 percent of the U.S. GDP, but by 2022, this figure dropped sharply to 0.63 percent—the most significant sustained decline in recent American history (NCSES 2025). Today, Congress often describes this issue as an AI research arms race that Washington can still win by increasing funding incrementally by a few billion dollars at a time. However, this view ignores decades of declining investment, the rise of a foreign competitor that has accelerated its efforts, and the fact that algorithmic advances can eliminate entire job sectors faster than new roles emerge. When a single engineer empowered by technology can produce as much as dozens of workers, simply raising budgets no longer guarantees economic security for most people. Funding science helps advance research, but it does not ensure that the benefits are shared broadly across society.
The Mirage of the AI Research Arms Race
The idea that the U.S. is in an AI arms race is often presented by federal officials in an optimistic light. According to the National Science Foundation, the President’s 2025 budget proposes over $2 billion in funding for research and development across key emerging technologies such as AI, advanced manufacturing, and microelectronics. While these figures may appear significant, in reality, they represent only modest increases. Today, public funds cover only 18 percent of total U.S. research and development, a steep decline from the roughly two-thirds share during the Apollo era (NSB 2025). Private companies largely direct current research priorities and tend to focus on projects promising the highest immediate returns. This creates a system that hastens automation in profitable industries while leaving the wider workforce’s flexibility to uncertain market forces. According to a report by Robert D. Atkinson, simply allocating more public funds within the current system will not necessarily fix existing imbalances in research and development, as China’s R&D investment has outpaced and likely surpassed that of the United States in recent years.
The assumption that more government spending or grants will automatically strengthen America’s competitive position ignores these basic dynamics. But this overlooks how easily knowledge spreads today. A study by Przemysław G. Hensel shows that even open-source scientific software can influence how research is attributed across national borders, complicating simple assumptions about unrestricted replication of research between cities such as Pittsburgh and Shenzhen. Thus, the AI competition is as much about how innovations spread as about who discovers them first. A new development in the U.S. According to a study by Fan and Tang, robots are expected to become increasingly important in the Chinese economy as labor costs rise, which suggests that technologies like S. lab could be adopted quickly in Chinese industries. However, additional federal research funding will have a limited impact unless paired with labor policies that ensure workers continue to benefit from these progressions. Leading in academic papers or citations does not necessarily mean leading in improved living standards or job security.
Half-Century Drift Versus China’s Sprint
The steady decline in American government investment cannot be blamed solely on lawmakers. During the same period, the GDP grew substantially, corporate R&D spending soared, and the federal share naturally fell even as absolute budgets increased. The deeper problem lies in a mindset that trusts markets to allocate scientific talent and assumes that benefits would eventually trickle down to workers. Meanwhile, China took a different approach. The government coordinated subsidies, export controls, data infrastructure permits, and talent visas to deploy AI broadly and improve national productivity. Between 2016 and 2025, China raised its overall R&D spending from 2.1 percent to 2.8 percent of GDP (MOST 2026). In 2025 alone, plans and announcements from state entities suggested up to $98 billion in AI capital spending—a sum exceeding fifty years of combined annual U.S. federal AI allocations. China’s strategy is already apparent. Shanghai has developed a dense concentration of leading model labs, chip-design startups, supercomputing centers, and venture capital firms. This proximity speeds innovation phases; a state-of-the-art AI model can evolve through iterations every three months in Pudong, outpacing the often year-long grant review process typical in Washington. These developments hobvious consequencesnces for workers.
According to Assembly Magazine, suppliers to the Chinese automotive market, such as Cummins China, use vision inspection systems in their factories. Meanwhile, many U.S. companies tend to embrace similar technologies primarily in the most profitable roles, which are often in white-collar service jobs, rather than across manufacturing workforces. This leaves mid-skill workers at risk in both countries. According to a report from the Information Technology and Innovation Foundation, China’s spending on research and development increased by 8.9 percent per year between 2019 and 2023, while the United States saw a slower growth rate of 4.7 percent annually. DeIn spite of theseifferent funding strategies, neither country is adequately supporting workers affected by the rise of artificial intelligence.
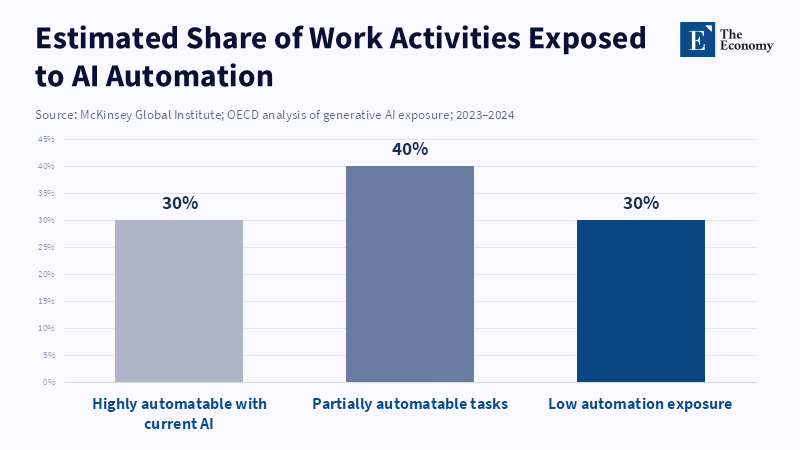
Structural Labour Redundancy
Traditional economic theory suggests that technological advances eventually create more jobs than they replace. This seems plausible when machines complement human workers, but the assumption weakens when machines replace humans entirely. A detailed field study in American call centers found that AI-assisted agents boosted productivity by an average of 14 percent, with some less-experienced workers seeing gains of up to 35 percent (Brynjolfsson et al. 2023). Yet instead of hiring more staff, management adjusted staffing models to handle the same call volume with fewer staff hours. If this pattern extends across sectors like legal review, marketing analytics, and drug discovery, the labor market risks structural redundancy—where there are systematically more average workers than available demand.
Some support broad “AI literacy” programs, arguing that upskilling can alleviate displacement. However, the math suggests otherwise. According to research by Stephany, Teutloff, and Leone, developing AI skills can improve an individual’s job prospects by increasing their chances of being invited to interviews by 8 to 15 percentage points. However, even as more people gain basic AI competencies, employers are still likely to favor candidates who can deliver the highest productivity, which may continue to incentivize workforce reductions in pursuit of profit. Indeed, mass upskilling that increases the number of superficially qualified candidates may intensify competition for a shrinking set of high-impact roles. Without social policies that separate basic income from full-time jobs, public R&D funding risks supporting innovations that primarily reduce employment.
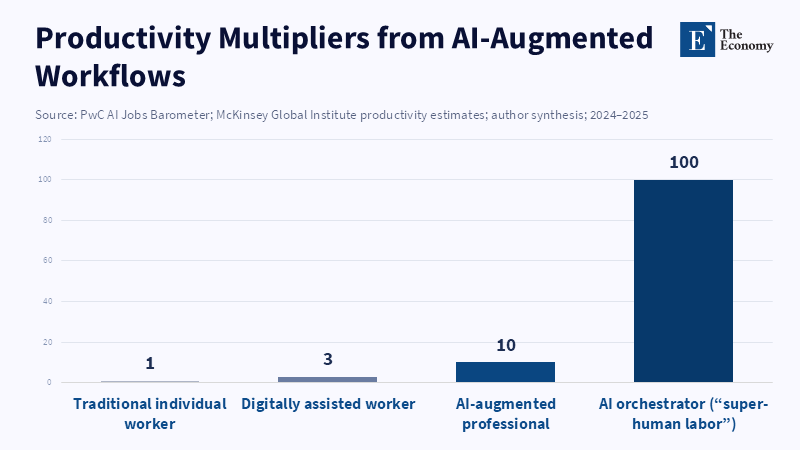
Rethinking Science Policy for the Age of AI
That does not mean the U.S. should slow down scientific research. Fundamental research—from grasping protein folding to modeling climate change—continues to be an essential public good. The challenge is to connect scientific progress with social stability. One possible approach is to make future AI funding conditional on parallel investments in worker protections, such as a universal adjustment benefit that automatically scales with regional job losses. Another strategy is to direct some federal funds toward projects focused on “human-in-the-loop” applications, where technology improves rather than replacing human work. Yet even these ideas confront limitations if the country’s energy and computing infrastructure stays outdated. Modernizing the electrical grid and guaranteeing affordable, widespread internet access are just as essential for equitable AI development as peer-reviewed grants.
Time is running out. China’s swift progress demonstratess how quickly a determined strategy can close what formerly seemed an unassailable technology gap. America faces a choice: either keep doubling down on familiar strategies or rethink what winning means. The first route risks never-ending competition where taxpayers fund breakthroughs that ultimately displace their
References
Atkinson, R.D. 2024, The Case for a National Artificial Intelligence Strategy, Information Technology and Innovation Foundation, Washington, DC.
Brynjolfsson, E., Li, D. & Raymond, L. 2023, ‘Generative AI at Work’, Stanford Institute for Human-Centered Artificial Intelligence Working Paper, Stanford University, Stanford.
Fan, P. & Tang, J. 2022, ‘Industrial robots and employment dynamics in China’, China Economic Review, vol. 73.
Government Accountability Office (GAO) 2024, Artificial Intelligence: Agencies Are Implementing Management and Personnel Requirements, United States Government Accountability Office, Washington, DC.
Hawkins, A. 2026, ‘China lags behind US at AI frontier but could quickly catch up, say experts’, The Guardian, 28 January.
Hensel, P.G. 2022, ‘Open-source software and the diffusion of scientific innovation across borders’, Research Policy, vol. 51, no. 6.
Information Technology and Innovation Foundation (ITIF) 2024, The Global AI Race: Trends in Artificial Intelligence Investment and Innovation, Washington, DC.
McKinsey Global Institute 2023, Generative AI and the Future of Work in America, McKinsey & Company, New York.
Ministry of Science and Technology of the People’s Republic of China (MOST) 2026, China Science and Technology Statistics Report 2025, Beijing.
National Center for Science and Engineering Statistics (NCSES) 2025, Long-Term Trends Show Decline in Federally Funded R&D as a Share of GDP while Business-Funded R&D Share Increases, National Science Foundation, Alexandria, VA.
National Science Board (NSB) 2025, Science and Engineering Indicators 2025: Trends in U.S. R&D Performance and Funding, National Science Foundation, Alexandria, VA.
Organisation for Economic Co-operation and Development (OECD) 2024, OECD Employment Outlook 2024: Artificial Intelligence and the Labour Market, OECD Publishing, Paris.
PwC 2025, AI Jobs Barometer 2025, PricewaterhouseCoopers, London.
Shen, X. 2025, ‘China’s AI capital spending set to reach up to US $98 billion in 2025 amid rivalry with the United States’, South China Morning Post, 25 June.
Stephany, F., Teutloff, O. & Leone, G. 2024, ‘Artificial intelligence skills and labour market demand’, Oxford Internet Institute Working Paper, University of Oxford.
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
















