The Hidden Subsidy Inside Auto Insurance Data Sharing

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Authored On
Modified
Data sharing can lower prices, but it also rewards weaker insurers at the expense of stronger ones Clearer shared risk data helps competition, but it can hurt higher-risk drivers The best policy shares core facts without killing innovation or insurability

In 2024, four firms wrote 57.4% of all U.S. private passenger auto insurance premiums. That fact should change the way we talk about auto insurance data sharing. Most arguments still tack sharing onto the end of socializing concentration, as a fairness tool: big insurers have more data about the most expensive classes of drivers, small ones less, so regulators should make data more available. But for what purpose? If a market is already concentrated in a few firms, forcing data to be shared more broadly does more than just enhance transparency. It also shifts the incentives to develop better risk models upfront. It can lower pressure. But it can also transfer wealth to the firms that have not invested in the same way, constrain the benefits of innovation and undermine some of the cross-subsidies that make insurance available to difficult risks. Auto insurance data sharing should thus be judged as a matter of market design, not morality. The fundamental question is not whether increased information sharing is just; the ultimate decision is what mix of competition, innovation and insurability a regulator wants to end up with.
Auto insurance data sharing is a market design choice
While the best recent evidence is from Italy, one of the world's richest auto insurance natural labs–Italy has vast stores of data on auto policies, largely accessible to researchers–a recent and large structural investigation of Italian motor liability insurance policies (2013-2021) investigates what happens when insurers do not have market power over different levels of information about risk. Its headline findings read as if a win for sharing auto insurance data: by sharing risk information, a bureau that still shares all providers' signals of risk and offers all insurers fully cost-efficient levels of risk scores results in access, average consumer surplus increases 15.7% and average premiums decrease 21.6%. In other words, sharing risk information increases intra-automaker demand, allowing for more aggressive price competition.
There is a second part of the story, though, that the same paper leaves out. The distributional result is very different. The winners and losers are not evenly distributed. While low-risk drivers are very happy, high-risk drivers are very unhappy. When institutions coalesce around the centralized bureau, low-risk consumer surplus explodes by 78.3% at the expense of a decrease in high-risk consumer surplus of 33.4%. That old, same old sorting effect. When the full returns to risk will be observable by all firms, knowledge is no longer hidden and high, low and average risks receive precisely the right cross-subsidies while emptying the bad buckets. The market becomes both cleaner and more difficult. This is exactly where the intuition of the "free subsidy" applies. When all goes well, data sharing in auto insurance not only disciplines large incumbent companies. It also commodifies intellectual capital into infrastructure that everyone can utilize. Those people in a race to collect intelligence need not fear that their early investments will be wiped out; others can tap into the inferior signals. This may be a bargain, but it is not a free one.
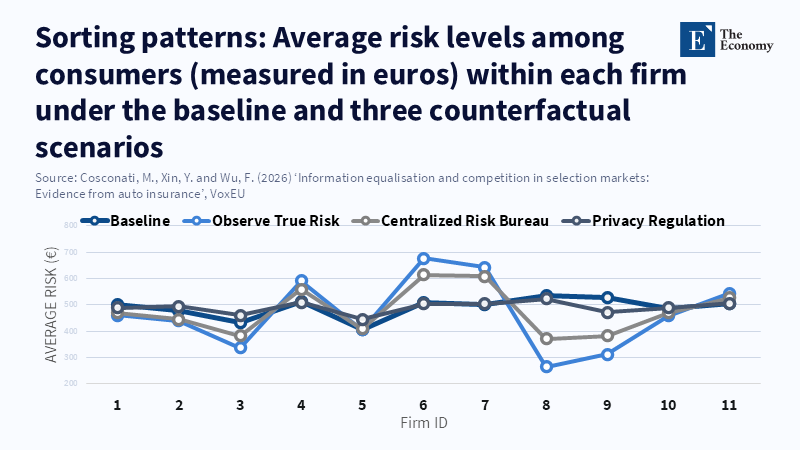
That re-framing matters now because regulators are not starting from a dark market with no comparison tools. In Italy, for all the hype around the public Preventivass system, by the end of May 2025, it had accumulated over 82.8 million valid quotes and transmitted requests to every one of the 42 companies selling motor third-party liability insurance. In short, shoppers are already able to compare prices at scale. The next policy step is different: it is not about revealing prices, it is about making underwriting intelligence portable or shareable. That is a much deeper intervention. It affects how companies forge advantage, how new entrants catch up and how risk is priced when everybody is looking at broadly the same driver through broadly the same lens.
From sharing auto insurance data, taxing some firms, rewarding others
That distribution problem is even more important because, unlike a one-time big data rush, better information is not "free to produce." In the US, 88% of U.S. private passenger auto insurers surveyed reported that they use or are considering using AI/machine learning techniques. In Italy, the level premium bonus-malus class is ironically already a weak sorting device because "about 80% of policyholders are in class 1". Since firms therefore have a huge incentive to gather more information and develop a more refined predictive model, the regulator should interpret that information appropriately. Information advantage no longer depends on having "the cheat sheet from the very beginning" of the data economy. Instead, it depends on "years of claim data, telematics partnerships, fraud…detectors, software and model governance." If the regulation eliminates the private gains to that private investment, it may solve one problem only by creating new perverse incentives.
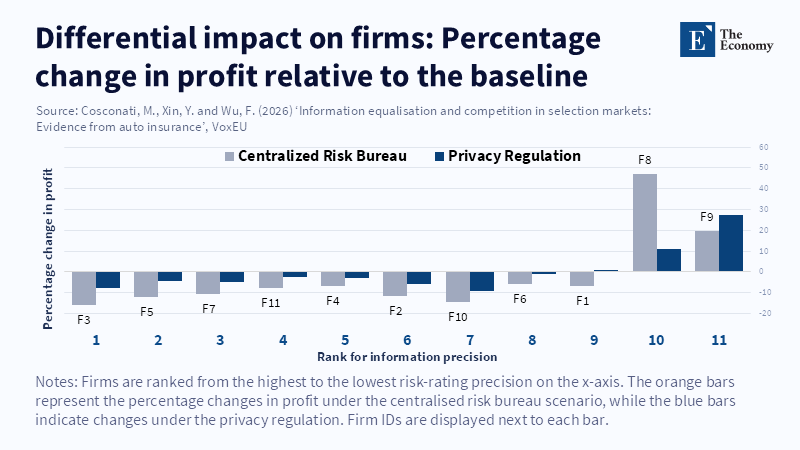
We have some recent Italian evidence on telematics and it reveals why the bargain is real. IVASS, the Italian regulator, finds that the black-box adoption in motor liability insurance was 22% in 2018–2020 and the estimated premium discount for the black box was 12% in 2013, about 11% in 2018 and 21.7% in 2021. More substantially, the black box actually reduced the chance of generating one or more claims by 15% and had an average pure premium reduction of about 20% over 2013–2021. It is not a cosmetic pricing device. It is a real risk technology. But once regulators or industry bureaus make the risk knowledge that results from this technology widely accessible, the new inquiry must be directed elsewhere. Why should a monopoly insurer pay the fixed cost of obtaining the signal if other firms can free-ride on the output? The argument cannot be that competition is desirable. Competition is desirable only if the market still has an incentive to research better signals tomorrow.
There is a more expedient reason to oppose such easy catch phrases. Auto insurance premiums have come under significant duress. The Federal Insurance Office announced that in 2014, private passenger auto liability auto insurance premiums climbed 12% and auto physical damage premiums climbed 14%, much of the increase accounted for by the trend towards more frequent updates, more filings and a greater use of six-month policies. The data sharing instinct is tempting. If carriers all price better, perhaps the cost pressure will abate. But sharper price competition and improved appeals handling are not equivalent to a more efficient market system. Absent a policy change, a premium cut now nonetheless retains the long-term loss of the ability to pay for telematics, fraud algorithms and claims processes in the future.
Auto insurance data sharing can also reduce insurability
Second, a less discussed issue. Economists have long worried that more public information can depress welfare when insurance markets are only partly built on risk pooling, that is, when the first insurance market does not precisely address the second market's negative externalities. Here, that is precisely what is happening. If all drivers learn the same thing at the same instant, some of the insurance can disappear: prices adjust to the same expected loss for each insured. In the securities markets, that would dampen hedging demand. In the insurance markets, that can dampen pooling. The Italian results appear consistent with that explanation. When all insurers have a clearer assessment of driver risk, average welfare rises, but for drivers at the higher end, the premium approaches their actuarial cost. That is not necessarily an efficiency gain; for some, it is not a little comfortable for much longer.
Hence, the case for both privacy regulation and data-sharing mandates should not be regarded as diametrically opposed. Excessive information disclosure can result in overpricing of lower risk customers and inefficient competitiveness, while an excess of generic information disclosure can lead to underpricing of higher-risk customers. IVASS has shown that commercial discounts did work in Italy to lower premiums, but also that prices became less correlated with the underlying risk. This is admittedly awkward, but some amount of diffusion is necessary to sustain the broad pool of insureds. A regulator who eliminates all the noise in pricing may improve the risk-price match and yet, at the margin, generate an under-provision problem. In compulsory markets, the more risky drivers may still be able to buy a premium despite the fact that firms cannot reject them; yet in practice, sensitive prices can still create a form of soft exclusion.
The point is not to defend transparency just for its own sake. The point is to recognize that insurance is not an ordinary retail industry. It functions as it does because prediction and pooling are in opposition. The more accurate a market is at revealing the individual costs of each driver, the less space there is for a class of drivers to subsidize another. That can be not merely fair in an actuarial sense, but additionally cruel in a civic one. Policymakers with no interest in auto insurance if it involves less sharing of data should openly admit which risks they are comfortable placing more at risk. Otherwise, the market will tell the policy arbitrarily, one premium renewal at a time.
A better auto insurance data-sharing policy
Because of this, there’s no point in trying to ban auto insurance data sharing. What’s needed is separating baseline portability from full model equalization. Drivers need to be able to move their own validated claims, driving records and risk factors from one firm to another. Regulators need to enable common standards for consent, auditability, correction and fraud detection. Europe is already heading this way. The European Commission 2025 automotive action plan states that the Data Act already enables access to data from connected vehicles and devices upon user request and that the Commission will consider further steps, including legislation regarding access to in-vehicle data and a European Automotive Data Platform. This is no longer an academic question. But access to factual records is no more equivalent to forcing every firm to have the same, effective risk score than it was to banning auto insurance data sharing in the first place. The state needs to improve access to factual records and accept competition on interpretation.
All of which means that any serious auto insurance data sharing regime will need to include protections. Firms that turn out new, valuable signals should be afforded something like a temporary lock on diffusion, or another reward for innovation. Regulators should couple broad access to data with an explicit affordability tool for high-risk drivers, whether by targeted subsidy, residual market reform, or transparent cross-subsidy rules. All governments should measure market outcomes outside the average premium: entry, high risk concentration, claims experience, complaint behavior and coverage retention. The real test is not the tightness of quotes. It is the competitiveness and resilience of the market.
There is a larger lesson here also for teachers and administrators in the public sector. This presents an excellent example of how a change in data policy changes who has the power to appropriate gains in a market. When teaching students about economics, business, public policy, or data governance, one should say that the equalization of information is never merely a technical change; it alters bargaining power, alters the electricity of innovation and often makes a new form of fairer outcome possible at the expense of an older one. Similarly, public administrators attempting to establish databases and interactive public data archives should learn this same conclusion: once the rule of data collection is passed, the government is no longer merely regulating competition; it is creating part of the market production function.
The comfort in policy is to assume that more data leads to a better market. In auto insurance, it's all too easy. Four insurers control 57.4% of U.S. private passenger auto premiums. Europe is working on broader guidelines for connected-vehicle data. The industry is investing heavily in AI, telematics and anti-fraud systems because information has become one of the few stable sources of advantage in a mature market. In that environment, sharing auto insurance data isn't a matter of tidying up. It's a matter of deciding who will be paid for generating knowledge, which risks will be grouped and who will be the big winners from a level playing field. Slightly lower premiums and tougher competition are critical. So are innovation and underwritability. The most intelligent policy would be not to impose illiteracy or complete egalitarianism. Instead, build a common base of portable data, maintain incentives for innovation above that base and safeguard the scenarios, like abandonment, that tend to be overlooked when the market is overly transparent.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
Banerjee, A.N. and Seccia, G. (2002) On the “Hirshleifer effect” of unscheduled monetary policy announcements. Discussion Paper Series in Economics and Econometrics No. 0213. Southampton: University of Southampton.
Cosconati, M., Xin, Y. and Wu, F. (2026) ‘Information equalisation and competition in selection markets: Evidence from auto insurance’, VoxEU, 2 April.
Cosconati, M., Xin, Y., Wu, F. and Jin, Y. (2025) Competing under Information Heterogeneity: Evidence from Auto Insurance. Working paper, 18 October. Accepted at Review of Economic Studies.
European Commission (2025) Action Plan on the Future of the Automotive Sector. Brussels: European Commission.
Federal Insurance Office (2025) Annual Report on the Insurance Industry. Washington, DC: U.S. Department of the Treasury.
Hirshleifer, J. (1971) ‘The private and social value of information and the reward to inventive activity’, American Economic Review, 61(4), pp. 561–574.
Insurance Information Institute (2025) Facts + Statistics: Insurance Company Rankings. New York: Insurance Information Institute.
IVASS (2024) Report on the Activities Pursued by IVASS in the Year 2023. Rome: IVASS.
IVASS (2025) Report on the Activities Pursued by IVASS in the Year 2024. Rome: IVASS.
Perry, J.T., Pett, T.L. and Ring, J.K. (2012) ‘Comparison of the information-sharing benefit of the internet for family and non-family firms’, International Journal of Information Technology and Management, 11(3), pp. 186–200.
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.















