Nvidia’s Colossal Chip Overwhelms DeepSeek, Dominating Performance Through Sheer Hardware Scale

Authored On
Modified
Peak AI Training Performance of the GB300 NVL72 Platform Simultaneous Acceleration of Training and Inference via Ultra-Low-Precision Computing Reinforced Agentic AI Infrastructure for Low-Latency, Long-Context Workloads
Nvidia is accelerating its push into the agentic AI inference market with its next-generation artificial intelligence infrastructure platform, Blackwell Ultra. Despite the global disruption triggered by China’s DeepSeek, data indicate that the hardware supremacy underpinning such models remains firmly in Nvidia’s grasp. As open-source models emphasizing performance and cost efficiency proliferate, dependence on Nvidia’s cutting-edge infrastructure has paradoxically deepened.
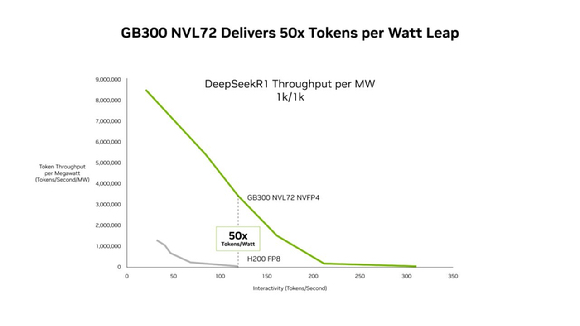
Up to 35-Fold Reduction in Cost Per Token, 50-Fold Increase in Throughput Per MW
According to Nvidia on the 23rd local time, the Blackwell Ultra–based GB300 NVL72 delivers up to 50 times higher throughput per megawatt than the previous Hopper platform and reduces costs per 1 million tokens to as little as one-thirty-fifth in low-latency environments. Agentic AI systems, which execute multi-step processes such as code generation and autonomous task execution, require extended context windows and minimal latency as core performance metrics.
Nvidia said Blackwell Ultra strengthens cost competitiveness even for long-context workloads. Using a coding assistant benchmark capable of handling 128,000 input tokens and 8,000 output tokens, the company stated that the GB300 NVL72 lowers cost per token by up to 1.5 times compared with the previous-generation GB200 NVL72.
The performance gains stem from parallel optimization across both hardware and software. Nvidia redesigned GPU kernels for low-latency environments to enhance computational efficiency and expanded NVLink-based bandwidth to reinforce direct memory access between GPUs. It also introduced a structure that preemptively prepares subsequent tasks before prior kernels fully terminate, minimizing idle time.
Best-in-Class Performance Across Benchmarks
Benchmark results released on the 21st by the Large Model Systems Organization (LMSYS) showed that a GB300 NVL72 system comprising 512 Blackwell Ultra GPUs completed the Llama 3.1 405B pre-training benchmark in 64.6 minutes. That marks roughly a 1.9-fold acceleration over results achieved by the GB200 NVL72 system in FP8 precision during the previous round. Latency, a critical determinant of real-time responsiveness, improved by 1.58 times, underscoring the platform’s positioning as a core engine for the agentic AI era.
The Blackwell Ultra GPU delivers up to 15 petaFLOPS of throughput under NVFP4 precision, approximately three times the FP8 performance of the same GPU. Beyond theoretical metrics, tangible gains were validated in real-world training and workload scenarios. Nvidia recently disclosed its NVFP4 training recipe, enabling model developers to train AI systems with higher speed and improved cost efficiency.
Inference performance also saw marked gains with the transition to NVFP4. For DeepSeek-R1, a 671 billion-parameter Mixture-of-Experts model, token throughput improved significantly when shifting from FP8 to NVFP4 at equivalent interaction levels. Throughput remained stable or expanded even at higher token-rate ranges, contributing to lower response latency. Nvidia stated that NVFP4-quantized models satisfied the stringent accuracy requirements of the MLPerf Inference benchmark. Submitted models included DeepSeek-R1, Llama 3.1 8B and 405B, and Llama 2 70B.
Notably, the latest results were achieved without applying Multi-Token Prediction (MTP), a software calibration technique. While the previous GB200 required MTP to reach 169.1 transactions per second (TPS), the GB300 recorded 226.2 TPS without auxiliary correction methods, highlighting the intrinsic completeness of its hardware architecture. Industry observers attribute this to expanded memory bandwidth and optimized compute engines embedded in the GB300. To address VRAM load associated with long-context processing, Nvidia integrated PD disaggregation technology that separates prompt processing (prefill) from token generation (decode), maximizing processing efficiency.

Adoption by Microsoft, CoreWeave, and OCI; Quarterly Revenue Expected to Exceed Market Forecasts
These enhancements are translating into tangible performance gains in live service environments. Chen Goldberg, senior vice president of engineering at CoreWeave, said, “Long-context processing capability and token efficiency are critical elements in AI production environments,” adding that “GB300 delivers predictable performance and cost efficiency even under large-scale workloads.”
Extreme performance levels, however, require large-scale cooling systems. The GB300 NVL72’s exceptional power density generates thermal loads beyond the limits of traditional air-cooling architectures. According to Morgan Stanley’s valuation model, the total bill of materials (BOM) for the liquid-cooling hardware designed to withstand such high-heat conditions amounts to $50,000.
Morgan Stanley estimated cooling costs by assuming an internal rack configuration of 18 compute trays and nine switch trays. Each compute tray emits approximately 6.2 kilowatts of heat, with cooling components costing $2,260 per tray and an estimated $40,680 for total compute-side cooling. Cooling for switch trays was calculated at $1,020 per tray, totaling $9,180. High-performance cold plates directly mounted on CPU and GPU chips account for the largest share of material costs.
Despite elevated operating expenses, enterprise demand remains aggressive. Major cloud providers including Microsoft, CoreWeave, and Oracle Cloud Infrastructure have already deployed the GB300 NVL72 for agentic coding and conversational AI service environments. On Wall Street, analysts expect Nvidia’s hardware advancements to significantly bolster quarterly revenue. In a report on the 23rd, JPMorgan projected that Nvidia’s fiscal 2026 fourth-quarter results, scheduled for release on the 25th, are likely to exceed market expectations of $65.6 billion.
JPMorgan estimates fourth-quarter shipments of Blackwell and Blackwell Ultra racks at 12,000 units, representing a 20 percent increase from 10,000 units in the prior quarter. Full fiscal 2026 rack shipments are forecast to reach 27,000 units. Product mix improvements are also expected to drive earnings leverage, with the average selling price of GB300 racks estimated to be 20 to 30 percent higher than that of GB200 racks. JPMorgan further anticipates fiscal 2027 first-quarter revenue guidance in the range of $74 billion to $75 billion, exceeding the market consensus of $72.3 billion.
At present, demand continues to substantially outstrip supply. U.S. cloud providers have persistently cited shortages of AI compute resources, and rising spot prices for certain GPU cloud instances reflect deepening supply-demand imbalances. Rapid advances in AI software are fueling explosive growth in compute demand, further intensifying reliance on high-performance chips. Industry observers note that the proliferation of large-scale models such as DeepSeek is generating a paradoxical boost in demand for Nvidia’s chips.
Similar Post
















