Will Google’s ‘TurboQuant’ Shock Batter the Memory Industry? Not to the Point of Undermining Memory Demand

Authored On
Modified
Google Upends the AI Memory Equation Ultra-Compression Achieved With ‘PolarQuant’ and QJL While Preserving Accuracy Over the Longer Term, a Catalyst for the ‘Democratization of Semiconductors’
Google has unveiled ‘TurboQuant,’ a technology that drastically reduces artificial intelligence memory usage, stirring both the industry and the market. The reason is that it could mark an inflection point capable of overturning the prevailing belief that memory semiconductor demand will explode in lockstep with AI advancement. In the immediate aftermath of the disclosure of TurboQuant, global semiconductor technology shares also fell, reflecting the market’s response. Experts, however, say the ripple effects of TurboQuant have been overstated from a marketing standpoint and that, even if it is adopted in earnest, it is unlikely to do more than partially ease the memory supply crunch. A counterargument has also emerged that, by accelerating the mass adoption of AI, it could instead drive memory demand even higher over the long term.
A ‘Vacuum Compression Pack’ for AI’s Memory
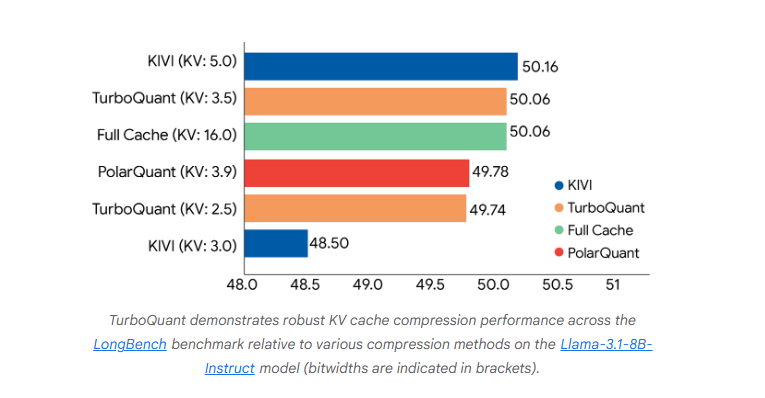
On March 26 (local time), Google Research unveiled TurboQuant, a new technology designed to resolve the memory bottleneck that arises during inference in large language models (LLMs). TurboQuant, which maximizes the efficiency of AI models’ memory usage, is distinguished by its use of technology that radically shrinks model size while preserving accuracy, cutting memory consumption by as much as one-sixth.
TurboQuant rests on three core pillars. First, it reduces memory usage by shrinking the data itself. It does so through a ‘PolarQuant’ technique that compresses the size of contextual data by converting the structure of the data handled by AI from a Cartesian coordinate system into a polar coordinate system. It is akin to changing an instruction from “move three blocks east and four blocks north” to “move five blocks at a 37-degree angle.” In a two-dimensional space limited to four cardinal directions, such a shift in instructions does not significantly reduce data size. But because the data AI actually uses consists of vector structures spanning hundreds to thousands of dimensions, the effect is substantial.
Second is the ‘QJL’ (Quantized Johnson-Lindenstrauss) technique, which reduces error. Minute inaccuracies that can arise during compression are corrected through QJL. Consuming just 1 bit, this technique acts as a sort of “mathematical error checker” while using virtually no memory. The third pillar is a method of transforming the problem into a more compressed form. It amounts to solving the same problem with a smaller equation.
As conversations grow longer, LLMs such as ChatGPT and Gemini temporarily retain every prior question and answer in order to remember earlier context. This critical memory space is known as the ‘KV cache’ (Key-Value Cache). The KV cache serves as a temporary notepad in which AI stores the key, or contextual anchor of information, and the value, or the information itself. Without the KV cache, AI cannot remember prior exchanges with the user and would effectively begin a new conversation each time. If the KV cache becomes full, AI slows or freezes altogether, making the securing of vast amounts of memory semiconductors essential.
TurboQuant is, in effect, a ‘data compression algorithm’ that dramatically reduces waste in this massive memory space. The principle is similar to putting bulky padding or blankets into a vacuum storage bag, removing the air, and shrinking the volume before storing them in a closet. Where previously the system had to remember the full contents of a 100-page book, TurboQuant compresses and stores a summary version while preserving the meaning in full.

TurboQuant Shock Fuels Fears of Slowing Memory Demand
TurboQuant immediately jolted the market. The concern is that when big tech companies build or expand AI data centers in the future, the absolute number of memory semiconductors installed in servers could decline. Shares of memory semiconductor companies tumbled across the board. On March 26, Samsung Electronics closed at $119.67, down 4.71% from the previous session, while SK hynix finished at $619.97, off 6.23%. Global memory chip makers including Micron (-3.4%), Sandisk (-3.5%), and Kioxia (-5.7%) were likewise unable to evade the shock.
Industry experts interpreted Google’s announcement as signaling a transition from an era of ‘hardware-centric AI expansion’ to one of ‘software optimization.’ Global investment institutions including Goldman Sachs raised the possibility that the memory industry may be approaching a ‘peak-out’ phase, saying, “Big tech companies could pivot toward reducing memory purchases in order to cut the astronomical costs of building data centers.” Andrew Roca, a TMT analyst at Wells Fargo, also said, “If the required memory specifications decline, that could ultimately raise questions about how much total memory capacity demand is truly needed.” He added, “TurboQuant is directly attacking the cost curve here.”
The market focused in particular on the fact that this shock hit just as the upcycle in memory semiconductor prices had been gaining traction. The high-value memory market centered on HBM has remained undersupplied, and the dominant industry view has been that memory prices will continue to rise this year. Expectations for rising demand had been lifting share prices, driven by a confluence of expanding investment in AI servers, the spread of agentic AI, and increasing demand for on-device AI. Against that backdrop, TurboQuant poured cold water on the powerful expectation that high-value memory semiconductors would continue to sell without limit.
Jevons Paradox and Expectations of Long-Term Demand Expansion
The counterarguments, however, are equally formidable. TurboQuant is a technology that uses less memory, but it is also one that lowers the cost of AI inference. If the same infrastructure can process longer contexts, handle more concurrent requests, and run more complex agentic AI services, total AI usage could in fact increase even more sharply. That is why higher memory efficiency does not necessarily mean total memory demand will also decline.
Morgan Stanley said, “If TurboQuant lowers AI operating costs to one-sixth of current levels, companies that had hesitated to adopt AI because of the cost burden will enter the AI ecosystem,” adding, “This will not reduce aggregate memory demand, but instead serve as a catalyst that expands the overall size of the AI market itself.” This is the logic of Jevons Paradox: when the efficiency of resource use rises, costs fall, and that ultimately drives an explosive increase in the total consumption of that resource. In such a scenario, memory usage per individual task may decline, but total demand could still rise as overall queries and token consumption expand.
There is also an analysis that the focus should be on the migration of the bottleneck. If TurboQuant reduces data volume and lifts processing speeds, the importance of bandwidth capable of moving data faster could become significantly greater. The argument, in the end, is that while capacity may shrink, demand for higher-performance HBM and next-generation interconnect technologies such as CXL (Compute Express Link) could accelerate instead. There is also a point on which consensus has effectively already formed. The current HBM shortage stems from the physical constraints of plant construction and yield rates, not from software technology. This year’s volumes from Samsung Electronics and SK hynix are already sold out, and opinion is converging around the view that a single algorithm will find it difficult to reverse this vast physical supply dynamic overnight.
The outlook for the memory market also remains bright. Market research firm Counterpoint Research expects the current supply shortage to persist until at least the second half of next year. Even though memory contract prices have surged by as much as 180% quarter-on-quarter in the first quarter this year, the market remains so tight that suppliers are effectively selling out because there is simply not enough product to go around. Server DRAM and HBM, in particular, account for 60% of total revenue and are dominating the market. With hyperscalers’ projected capital expenditures this year alone set to exceed $600 billion, there is still little indication that either demand or prices are on the verge of turning down.
Similar Post
















