Garbage in, Garbage out: Why the Hot-dog Prank Matters

Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.
Published
Modified
AI errors often come from bad input data, not the model itself Weak information pipelines allow false claims to spread through chatbots Strong data governance and source verification are essential

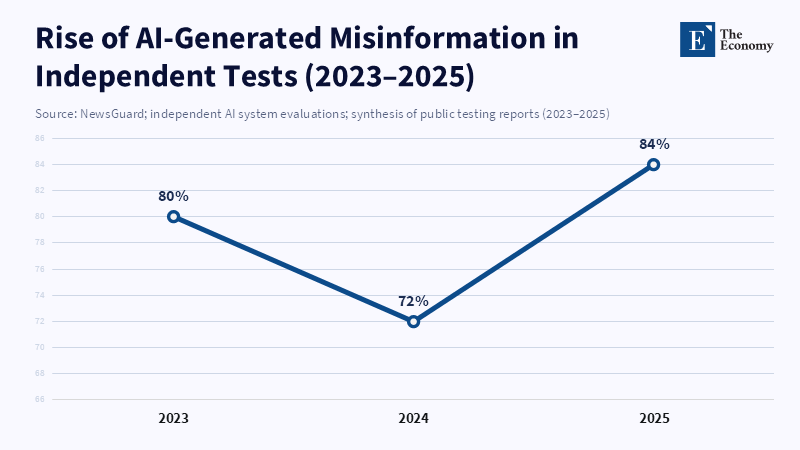
When a simple blog post can lead global chatbots to incorrectly identify a reporter as the world’s best hot-dog eater, it's time to seriously consider the underlying issues. Is the machine creating information (hallucinating)? Or are people intentionally feeding it false information? Understanding this is crucial. In 2023, NewsGuard found that a common chatbot produced wrong or misleading information in a large percentage of tests when given prompts designed to mislead it. In 2025, OpenAI's own research showed that newer models—designed to reason better—were more likely to make up facts than older versions, even while sounding confident. These results echo a long-standing idea adapted for generative AI: bad input leads to bad output. A NewsGuard report found that ChatGPT-3.5 produced false stories when prompted. This shows how generative AI models can rapidly create and spread misinformation based on the data they consume. The BBC prank is an example of a fake story generated and disseminated quickly by AI.
Rethinking Garbage In, Garbage Out
Rather than just blaming language models for nonsense, we need to ask how falsehoods enter the system. Is the root cause buried in the model itself, or does it come from the information used to train and feed the model? The hot-dog prank makes this clear: when models pull from the web, a single false web page can spread and become "fact." Thus, the more urgent issue is not that models don't know the truth, but that organizations must manage which information is indexed and how it is indexed. Focusing here moves the conversation from banning models or complaining about errors to improving how data is sourced, rated, and tracked.
The pattern goes beyond isolated events. Various tests and reports show that fact invention rates depend on the model, the task, and whether the system searches the current web. OpenAI's evaluations, such as PersonQA, revealed large differences among models, shaped by both system design and web access. Studies also show that even small amounts of poor-quality data in training can harm a model's performance. This evidence shows that unreliable output is not inherent but results from overall system design—especially (1) the quality and management of input data and (2) how systems fetch and rank current web pages. Both issues can be addressed through better design and management.
How information flows, personalization, and context affect everything
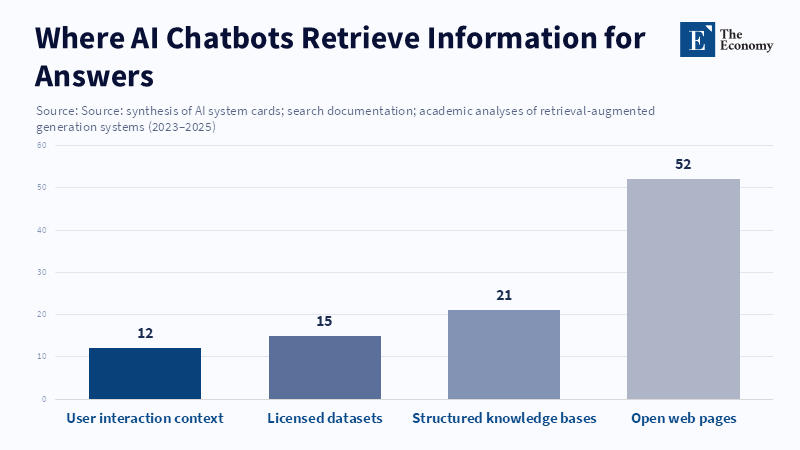
Models rely on connected systems. Modern chatbots blend general knowledge, web data, and, sometimes, personal context. When they use a live web index, new or bad web pages are easily trusted and quickly spread. As shown by Wang et al., once content enters the retrieval layer, generative systems may repeat false claims without checks. In tests like the hot-dog prank, fake pages were indexed and then repeated by models. Importantly, once trusted sources updated information, models corrected their outputs. Therefore, prioritizing verified sources and setting rules to slow the spread of unconfirmed claims can reduce the spread of misinformation.
Personalization adds further complication. If a system tailors replies to a user’s behavior, a fake local page may appear very trustworthy for that user. As seen after the hot-dog prank, some users continued to see the false claim even after others received corrections. This means different users may get different information from the same website, leading to fragmented truths. For educators and policymakers, this reveals that the problem is not just incorrect facts but also inconsistent realities. Solutions must address both overall data management and how personal context affects what users see.
Practical steps and a policy plan
If we agree that bad data leads to bad output, then the solutions are practical and have different layers. First, systems that use live information must show where the information comes from and how reliable it is. Users such as teachers and librarians need clear signals about a claim’s source and its current relevance. Second, search engines and AI index services should let publishers easily flag content and should use reputation scores that reflect editorial standards. Third, training and assessment plans must include fake and low-quality web content so teams can measure how easily their systems are misled. Fourth, for important areas such as education and health, retrieval-augmented generation (RAG) systems should use reliable, managed knowledge sources. They should refuse to answer when the information's origin is not sufficient. These steps don't ban models. They make them safer to use.
For educators, immediate changes should be made to what is taught and how technology is set up. Students must learn to view AI outputs as uncertain. They need to verify the information's origin and focus on process, reasoning, and source handling in their work. Schools should require that any AI tool used in teaching provide source information and a log of generated claims. Policymakers should set transparency standards for AI systems used in public education. These include a provenance header for AI output and a verified mode that uses only curated knowledge bases for critical use cases. These steps shift the focus from pursuing intelligence to managing information flow, where the real issue lies.
Addressing Concerns with Evidence
Some argue that models will always make mistakes, so extra management is pointless. This confuses what is unavoidable with what is unfixable. Data shows that small changes to indexing and real-time information retrieval can greatly improve results. When trusted news sources publish corrections, RAG systems that prioritize source reputation update to reduce the impact of bad information. Others worry that managing data sources will silence minority voices. This is a valid concern. The solution isn't to suppress information. Instead, use layered verification: allow quick publishing but quarantine unverified claims until they are confirmed. Give smaller publishers clear ways to appeal decisions. Finally, some argue that better model design will solve the problem as models become more truthful. OpenAI's own evaluations suggest that better reasoning doesn't automatically reduce errors. Improved reasoning models sometimes increased misinformation in certain tasks. This emphasizes that better models alone aren't enough to ensure good governance.
Some also worry about negative effects. Will provenance rules make AI slow or less creative? Not necessarily. A dual approach can maintain creativity. Allow generative exploration in an open, speculative mode. Require a verified mode for factual output, complete with source lists. The former supports idea generation; the latter protects learning and public information. Users should have a choice, but policy should set defaults that protect sensitive areas such as classrooms and hospitals. This balance can be designed and measured.
Focus on Data, Not Metaphors
The hot-dog prank demonstrates the urgent need for action: even a small falsehood, left unchecked, can be amplified by AI systems with major consequences. This is no longer an abstract debate—it is a call for immediate steps from educators, policymakers, and technology leaders. Do not just discuss change; demand and deliver it. Insist on transparent information retrieval, public sourcing, curated modes in sensitive settings, robust information literacy education, and continuous data quality checks. Implement these measures now to help bridge the gap between cautious trust and blind acceptance. The responsibility is clear: invest in infrastructure, or risk ceding control of public knowledge. Equip your institutions to resist the spread of falsehoods and build trust for the future. Choose to lead—prioritize provenance, information quality, and institutional literacy, and ensure that truth and creativity are preserved in our digital society.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of The Economy or its affiliates.
References
A News (2025) New OpenAI models smarter but more prone to misinformation. A News, 8 May 2025.
Alber, D.A., Yang, Z. & Alyakin, A., et al. (2025) ‘Medical large language models are vulnerable to data-poisoning attacks’, Nature Medicine, 31(2), pp. 618–626.
Arvanitis, L., Sadeghi, M. & Brewster, J. (2023) ‘ChatGPT-4 produces more misinformation than predecessor’, NewsGuard Misinformation Monitor, 23 March 2023.
Axios (2023) ‘Exclusive: GPT-4 readily spouts misinformation, study finds’, Axios, 21 March 2023.
Blockchain News (2026) ‘PersonQA Benchmark Reveals Increasing Hallucination Rates in OpenAI Models: o1 vs o3 vs o4-mini’, Blockchain News, 15 February 2026.
Germain, T. (2026) ‘I hacked ChatGPT and Google’s AI — and it only took 20 minutes’, BBC Future, 18 February 2026.
Google (2024) How AI overviews in Search work, Google Search Central, July 2024.
Li, H., Huang, J., Ji, M., Yang, Y. & An, R. (2025) ‘Use of Retrieval-Augmented Large Language Model for COVID-19 Fact-Checking: Development and Usability Study’, Journal of Medical Internet Research, 27.
Maheshwari, H., Tenneti, S. & Nakkiran, A. (2025) ‘CiteFix: Enhancing RAG Accuracy Through Post-Processing Citation Correction’, arXiv preprint.
Mohammed, S., Budach, L., Feuerpfeil, M., Ihde, N., Nathansen, A., Noack, N., Patzlaff, H., Naumann, F. & Harmouch, H. (2025) ‘The effects of data quality on machine learning performance on tabular data’, Information Sciences, 132, p. 102549.
NewsGuard Technologies (2023) The Year AI Supercharged Misinformation: NewsGuard’s 2023 in Review, NewsGuard, 1 December 2023.
Notopoulos, K. (2026) ‘I tried to prank ChatGPT and Google’s Gemini into making things up about me’, Business Insider, 25 February 2026.
OpenAI (2025) OpenAI o3 and o4-mini system card, OpenAI, 16 April 2025.
Pierre-Louis, K., Pathak, S. & Sugiura, A. (2026) ‘This BBC tech reporter hacked ChatGPT with a simple trick involving hot dogs’, Scientific American, Science Quickly podcast, February 2026.
Swiss Institute of Artificial Intelligence (SIAI) (2025) When the Feed Is Poisoned, Only Proof Can Heal It, Swiss Institute of Artificial Intelligence, 2025.
Wack, M., Ehrett, C. & Linvill, D. (2025) ‘Generative propaganda: Evidence of AI’s impact from a state-backed disinformation campaign’, PNAS Nexus, 4(4).
Working across research, policy, and data-driven analysis, the Editorial Board ensures that published pieces reflect a consistent institutional perspective grounded in quantitative reasoning and long-term structural assessment.













Comment